ここは、牛丼の写真からカロリーを算出してみよう!など、キャッチーな例題を掲載した、スクレイピングと機械学習の書籍のサポートページです。BeautifulSoup,scikit-learn,TensorFlowなど、さまざまなライブラリを実践で使うことに重きを置いています。
Pandasの最新バージョンではixが廃止されてしまいました。
ixをilocに置換すると動きます。
最新版のソースコードでは修正されています。
書籍の方、申し訳ありません。
置き換えて読んでいただければと思います。
以前はXMLでしたが、現在はZIPで圧縮されてしまっているようです。
# --- プログラム修正前
import os.path
# XMLをダウンロード --- (※1)
url = "http://www.city.yokohama.lg.jp/somu/org/kikikanri/data/shelter.xml"
savename = "shelter.xml"
if not os.path.exists(savename):
req.urlretrieve(url, savename)
# --- プログラム修正後
import os.path
import zipfile
# ZIPをダウンロード --- (※1)
url = "https://www.city.yokohama.lg.jp/kurashi/bousai-kyukyu-bohan/bousai-saigai/bosai/data/data.files/shelter.zip"
savezip = "shelter.zip"
savename = "shelter.xml"
if not os.path.exists(savezip):
req.urlretrieve(url, savezip)
# ZIPを解凍
with zipfile.ZipFile(savezip, 'r')as zf:
zf.extractall('./')
※なお、GitHubで公開されているファイルは修正済みです。
Windowsの場合は、以下のように、$HOME:$HOMEを{$HOME}:{$HOME}に変更して実行してください。
# p202
docker run -it \
-v {$HOME}:{$HOME} \
-p 8080:8080 mlearn
# p428
docker run -it -v {$HOME}:{$HOME} mlearn
cronの設定の記述(2カ所)で、「*」記号の前に改行が入ってしまっています。以下のように改行なしが正しい記述です。
PATH=/usr/local/bin:/usr/bin:/bin PYTHONIOENCODING='utf-8' 0 7 * * * python3 /home/test/everyday-kawase.py
なお、macOSでCRONを設定する場合、cronにフルディスクアクセスの権限を与える必要があります。こちらを参考にして権限を追加してください。
BeautifulSoup4.8.0にて、以下のようなエラーが出るという報告をいただいています。
AttributeError: 'NoneType' object has no attribute 'string'
以前のバージョンのBeautifulSoup4の『nth-of-type(n)』では、問題なかったのですが、最近のBeautifulSoup4では、動作が不安定なようです。
(参考)https://d.aoikujira.com/bbs/mbbs.php?m=thread&threadid=19
そこで、不安定な『nth-of-type(n)』を使わず、select("li")のように書くと良いでしょう。
本文は、以下のようになります。
ソースコードで、importの後の「*」が欠けています。
サンプルプログラムを参考にしてください。
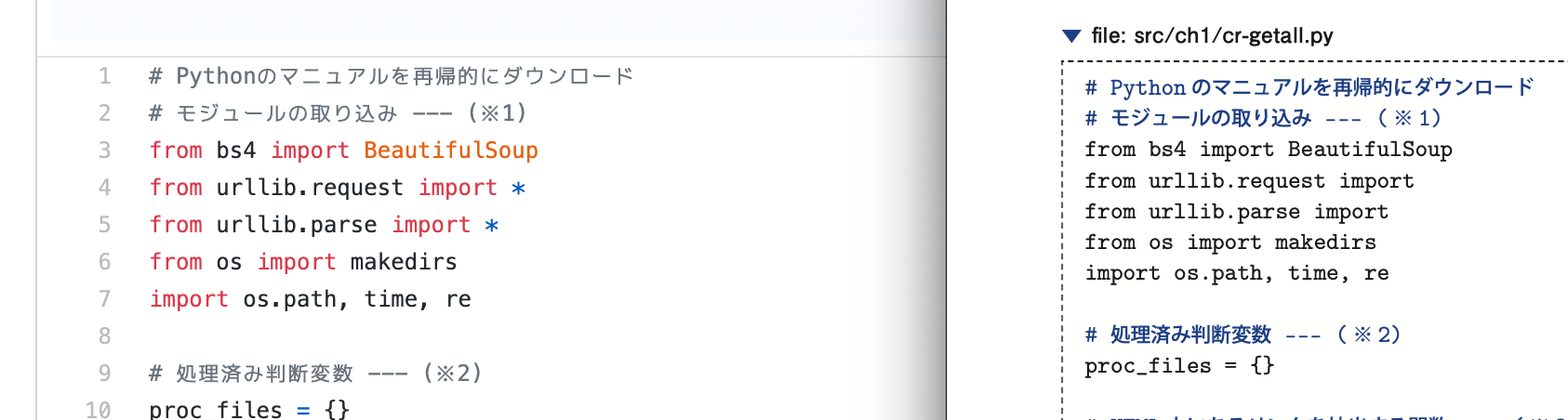
合ってもなくても動きますが、不要なコードが一行入っていました。
本書ではOpenCV3を利用していますが、OpenCV4になると、いくつかのメソッドの使い方が変わりました。理由は、OpenCV4以降、findContoursの返り値が変わったせいです。
いろいろ調べてみると、Docker for Windowsで、まれにマルチバイト文字が表示されないという問題があるでそうです。そこで、解決策としては、ConEmuなどの、DOSプロンプト以外のWindowsターミナル環境を使うと直るそうです。
本書のプログムは、Python3を対象にしています。pythonコマンドのバージョンがPython3であれば、そのまま利用できます。
wgetを利用して、本書のサンプルプログラムをダウンロードすると良いでしょう。
apt-get install wget wget http://www.socym.co.jp/download/1079/src.zip unzip src.zip
あるいは、ホスト側(Windows/macOS)にダウンロードしたファイルを、コンテナにコピーすることもできます。(参考)
本書は、執筆時点でのソフトウェアの使い方の操作について紹介したものです。ソフトウェアの性質上、どうしても、最新版では、動かなかったり、操作画面が変わってしまうということがあり得ます。
以下、最新バージョンでの操作方法を紹介します。
また、TensorFlowのインストールですが、Anacondaをインストールした後に、以下のコマンドを実行することでインストールが可能になっています。
# conda で TensorFlow 1.1.0 インストール $ conda install -c conda-forge tensorflow=1.1.0 # pip3 で keras をインストール $ sudo pip3 install keras==2.0.5
Kerasは、TensorFlowのバージョンに依存しています。本書5章のp240の手順に従ってインストールすると、TensorFlowのバージョンミスマッチが生じます。その場合、以下のように、モジュールが見当たらない旨のエラーが出ます。
ModuleNotFoundError: No module named ‘tensorflow.contrib.tensorboard'
その場合、この記事を書いた時点の最新のTensorFlowをインストールすることで、エラーを回避できます。
# conda で TensorFlow 1.1.0 インストール $ conda install -c conda-forge tensorflow=1.1.0 # pip3 で keras をインストール $ sudo pip3 install keras==2.0.5
また、上記の手順でインストールした、この記事を書いた時点の最新版(Tensorflow 1.1.0)では、APIの名前が変更になっています。主に、TensorBoardを使ったプログラムで変更が必要です。
変更点は、以下の通りです。
申し訳ありません、誤植がありました。
プログラムの一行目のfromの前にスペースが入っていました。スペースを削除すると動きます。
コメント部分にタイポ
先頭の図が「ぬけ」となっており、その後、図のキャプションが一つずつずれています。本来図の下のキャプションは次のようになるはずです。
崩れてしまっていますが、正しくは、以下の式が正しいです。
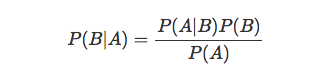
P.290 ~291のソースリスト「src/ch6/mlp3-classify.py」において、原稿執筆時に入力に使ったデータのパラメータが変わったため、入力データの不整合が発生しておりました。「mlp3-classify.py」を以下のように修正すると動作します。
# 最大単語数を指定 max_words = len(X[0])
このほかの部分も見直し、以下のように修正したファイルをzip形式でアップロードしてありますので、ご利用下さい。
9行目のmax_wordの定義を削除し、 16行目に、global max_wordsを追加 34行目に、max_words = len(X[0])を追加http://www.socym.co.jp/download/1079/mlp3-classify.zip
タイポでした。
ConEmu [URL] https://conemu.github.io/
本ページのコメント欄に、質問を書くと収集がつかなくなってしまいます。ご質問がある方は、「出版社のサポートページ」あるいは「くじらはんど・お問い合わせフォーム」でご連絡ください。
 クジラ机ブログ
クジラ机ブログ